 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarSim: Simulating Single-Chip Radar via Multimodal Neural Fields
May 25, 2026Radars are an ideal complement to cameras: both are inexpensive, solid-state sensors, with cameras offering fine angular resolution, while radars provide metric depth and robustness under adverse weather. However, radar data is more difficult to interpret than camera images and varies significantly between sensors, necessitating increased reliance on simulation for prototyping sensors and processing pipelines. Recent work treating radar reconstruction as a novel view synthesis problem has shown great promise in reconstructing radar-relevant geometry and simulating low-level radar data. However, such methods are constrained by the low spatial resolution of the underlying radar. To address this, we propose a unified differentiable renderer, RadarSim, which leverages the high angular resolution of RGB cameras to generate Doppler radar range images from a camera-initialized neural field. Using a novel data set of calibrated radar camera recordings from a custom hand-held rig, we demonstrate that RadarSim produces sharper geometry and Doppler range frames than radar-only reconstructions.
Elastic Attention Cores for Scalable Vision Transformers
May 12, 2026Vision Transformers (ViTs) achieve strong data-driven scaling by leveraging all-to-all self-attention. However, this flexibility incurs a computational cost that scales quadratically with image resolution, limiting ViTs in high-resolution domains. Underlying this approach is the assumption that pairwise token interactions are necessary for learning rich visual-semantic representations. In this work, we challenge this assumption, demonstrating that effective visual representations can be learned without any direct patch-to-patch interaction. We propose VECA (Visual Elastic Core Attention), a vision transformer architecture that uses efficient linear-time core-periphery structured attention enabled by a small set of learned cores. In VECA, these cores act as a communication interface: patch tokens exchange information exclusively through the core tokens, which are initialized from scratch and propagated across layers. Because the $N$ image patches only directly interact with a resolution invariant set of $C$ learned "core" embeddings, this yields linear complexity $O(N)$ for predetermined $C$, which bypasses quadratic scaling. Compared to prior cross-attention architectures, VECA maintains and iteratively updates the full set of $N$ input tokens, avoiding a small $C$-way bottleneck. Combined with nested training along the core axis, our model can elastically trade off compute and accuracy during inference. Across classification and dense tasks, VECA achieves performance competitive with the latest vision foundation models while reducing computational cost. Our results establish elastic core-periphery attention as a scalable alternative building block for Vision Transformers.
Building a Precise Video Language with Human-AI Oversight
Apr 22, 2026Video-language models (VLMs) learn to reason about the dynamic visual world through natural language. We introduce a suite of open datasets, benchmarks, and recipes for scalable oversight that enable precise video captioning. First, we define a structured specification for describing subjects, scenes, motion, spatial, and camera dynamics, grounded by hundreds of carefully defined visual primitives developed with professional video creators such as filmmakers. Next, to curate high-quality captions, we introduce CHAI (Critique-based Human-AI Oversight), a framework where trained experts critique and revise model-generated pre-captions into improved post-captions. This division of labor improves annotation accuracy and efficiency by offloading text generation to models, allowing humans to better focus on verification. Additionally, these critiques and preferences between pre- and post-captions provide rich supervision for improving open-source models (Qwen3-VL) on caption generation, reward modeling, and critique generation through SFT, DPO, and inference-time scaling. Our ablations show that critique quality in precision, recall, and constructiveness, ensured by our oversight framework, directly governs downstream performance. With modest expert supervision, the resulting model outperforms closed-source models such as Gemini-3.1-Pro. Finally, we apply our approach to re-caption large-scale professional videos (e.g., films, commercials, games) and fine-tune video generation models such as Wan to better follow detailed prompts of up to 400 words, achieving finer control over cinematography including camera motion, angle, lens, focus, point of view, and framing. Our results show that precise specification and human-AI oversight are key to professional-level video understanding and generation. Data and code are available on our project page: https://linzhiqiu.github.io/papers/chai/
Novel View Synthesis as Video Completion
Apr 09, 2026We tackle the problem of sparse novel view synthesis (NVS) using video diffusion models; given $K$ ($\approx 5$) multi-view images of a scene and their camera poses, we predict the view from a target camera pose. Many prior approaches leverage generative image priors encoded via diffusion models. However, models trained on single images lack multi-view knowledge. We instead argue that video models already contain implicit multi-view knowledge and so should be easier to adapt for NVS. Our key insight is to formulate sparse NVS as a low frame-rate video completion task. However, one challenge is that sparse NVS is defined over an unordered set of inputs, often too sparse to admit a meaningful order, so the models should be $\textit{invariant}$ to permutations of that input set. To this end, we present FrameCrafter, which adapts video models (naturally trained with coherent frame orderings) to permutation-invariant NVS through several architectural modifications, including per-frame latent encodings and removal of temporal positional embeddings. Our results suggest that video models can be easily trained to "forget" about time with minimal supervision, producing competitive performance on sparse-view NVS benchmarks. Project page: https://frame-crafter.github.io/
Steerable Visual Representations
Apr 02, 2026Pretrained Vision Transformers (ViTs) such as DINOv2 and MAE provide generic image features that can be applied to a variety of downstream tasks such as retrieval, classification, and segmentation. However, such representations tend to focus on the most salient visual cues in the image, with no way to direct them toward less prominent concepts of interest. In contrast, Multimodal LLMs can be guided with textual prompts, but the resulting representations tend to be language-centric and lose their effectiveness for generic visual tasks. To address this, we introduce Steerable Visual Representations, a new class of visual representations, whose global and local features can be steered with natural language. While most vision-language models (e.g., CLIP) fuse text with visual features after encoding (late fusion), we inject text directly into the layers of the visual encoder (early fusion) via lightweight cross-attention. We introduce benchmarks for measuring representational steerability, and demonstrate that our steerable visual features can focus on any desired objects in an image while preserving the underlying representation quality. Our method also matches or outperforms dedicated approaches on anomaly detection and personalized object discrimination, exhibiting zero-shot generalization to out-of-distribution tasks.
DetPO: In-Context Learning with Multi-Modal LLMs for Few-Shot Object Detection
Mar 24, 2026Multi-Modal LLMs (MLLMs) demonstrate strong visual grounding capabilities on popular object detection benchmarks like OdinW-13 and RefCOCO. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. While in-context prompting is a common strategy to improve performance across diverse tasks, we find that it often yields lower detection accuracy than prompting with class names alone. This suggests that current MLLMs cannot yet effectively leverage few-shot visual examples and rich textual descriptions for object detection. Since frontier MLLMs are typically only accessible via APIs, and state-of-the-art open-weights models are prohibitively expensive to fine-tune on consumer-grade hardware, we instead explore black-box prompt optimization for few-shot object detection. To this end, we propose Detection Prompt Optimization (DetPO), a gradient-free test-time optimization approach that refines text-only prompts by maximizing detection accuracy on few-shot visual training examples while calibrating prediction confidence. Our proposed approach yields consistent improvements across generalist MLLMs on Roboflow20-VL and LVIS, outperforming prior black-box approaches by up to 9.7%. Our code is available at https://github.com/ggare-cmu/DetPO
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
Dec 21, 2025We introduce CRISP, a method that recovers simulatable human motion and scene geometry from monocular video. Prior work on joint human-scene reconstruction relies on data-driven priors and joint optimization with no physics in the loop, or recovers noisy geometry with artifacts that cause motion tracking policies with scene interactions to fail. In contrast, our key insight is to recover convex, clean, and simulation-ready geometry by fitting planar primitives to a point cloud reconstruction of the scene, via a simple clustering pipeline over depth, normals, and flow. To reconstruct scene geometry that might be occluded during interactions, we make use of human-scene contact modeling (e.g., we use human posture to reconstruct the occluded seat of a chair). Finally, we ensure that human and scene reconstructions are physically-plausible by using them to drive a humanoid controller via reinforcement learning. Our approach reduces motion tracking failure rates from 55.2\% to 6.9\% on human-centric video benchmarks (EMDB, PROX), while delivering a 43\% faster RL simulation throughput. We further validate it on in-the-wild videos including casually-captured videos, Internet videos, and even Sora-generated videos. This demonstrates CRISP's ability to generate physically-valid human motion and interaction environments at scale, greatly advancing real-to-sim applications for robotics and AR/VR.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025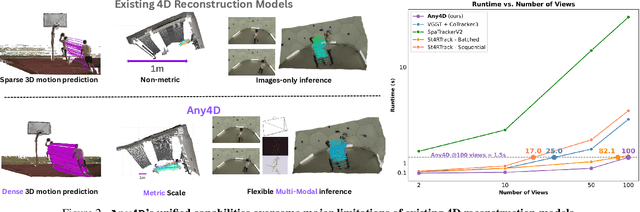
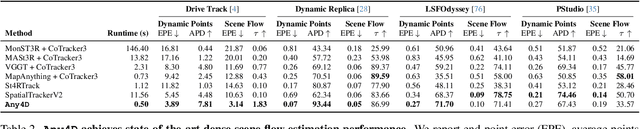
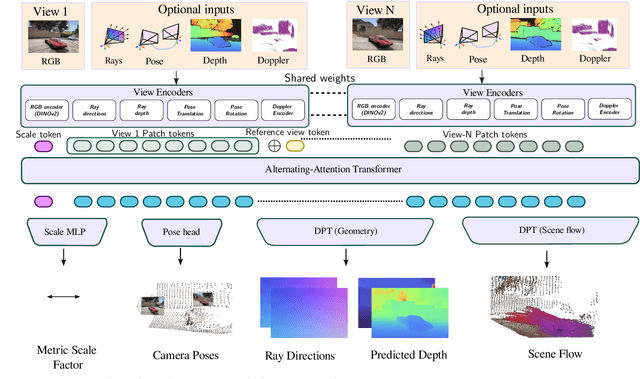
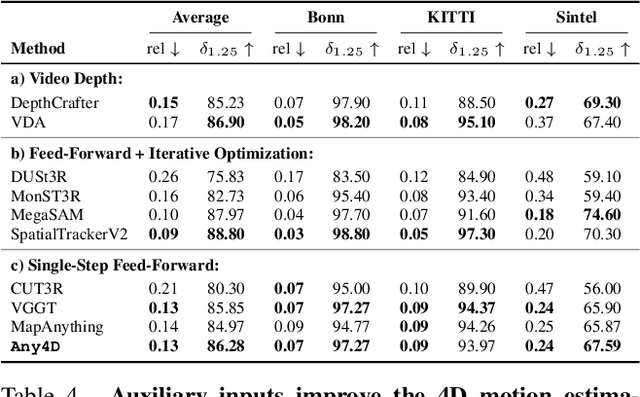
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
RF-DETR: Neural Architecture Search for Real-Time Detection Transformers
Nov 12, 2025Open-vocabulary detectors achieve impressive performance on COCO, but often fail to generalize to real-world datasets with out-of-distribution classes not typically found in their pre-training. Rather than simply fine-tuning a heavy-weight vision-language model (VLM) for new domains, we introduce RF-DETR, a light-weight specialist detection transformer that discovers accuracy-latency Pareto curves for any target dataset with weight-sharing neural architecture search (NAS). Our approach fine-tunes a pre-trained base network on a target dataset and evaluates thousands of network configurations with different accuracy-latency tradeoffs without re-training. Further, we revisit the "tunable knobs" for NAS to improve the transferability of DETRs to diverse target domains. Notably, RF-DETR significantly improves on prior state-of-the-art real-time methods on COCO and Roboflow100-VL. RF-DETR (nano) achieves 48.0 AP on COCO, beating D-FINE (nano) by 5.3 AP at similar latency, and RF-DETR (2x-large) outperforms GroundingDINO (tiny) by 1.2 AP on Roboflow100-VL while running 20x as fast. To the best of our knowledge, RF-DETR (2x-large) is the first real-time detector to surpass 60 AP on COCO. Our code is at https://github.com/roboflow/rf-detr
Towards Foundational Models for Single-Chip Radar
Sep 15, 2025mmWave radars are compact, inexpensive, and durable sensors that are robust to occlusions and work regardless of environmental conditions, such as weather and darkness. However, this comes at the cost of poor angular resolution, especially for inexpensive single-chip radars, which are typically used in automotive and indoor sensing applications. Although many have proposed learning-based methods to mitigate this weakness, no standardized foundational models or large datasets for the mmWave radar have emerged, and practitioners have largely trained task-specific models from scratch using relatively small datasets. In this paper, we collect (to our knowledge) the largest available raw radar dataset with 1M samples (29 hours) and train a foundational model for 4D single-chip radar, which can predict 3D occupancy and semantic segmentation with quality that is typically only possible with much higher resolution sensors. We demonstrate that our Generalizable Radar Transformer (GRT) generalizes across diverse settings, can be fine-tuned for different tasks, and shows logarithmic data scaling of 20\% per $10\times$ data. We also run extensive ablations on common design decisions, and find that using raw radar data significantly outperforms widely-used lossy representations, equivalent to a $10\times$ increase in training data. Finally, we roughly estimate that $\approx$100M samples (3000 hours) of data are required to fully exploit the potential of GRT.